ARM, x86 and a brief introduction to processors.
The performance of a processor is influenced by various factors. From a technical standpoint, processors operating at higher frequencies are capable of performing more operations per unit of time, but this also implies a higher energy consumption. For instance, a processor with a frequency of 3.4GHz can execute 3.4 billion cycles per second. Depending on the maximum number of instructions per cycle (max-IPC) that the processor is capable of executing, this results in a performance of 7 to 10 billion instructions per second, considering a single core. Therefore, ideally, for benchmarks, a processor that maximizes the number of instructions executed each cycle is more desirable.
In the market, there are two predominant processor architectures: ARM, which follows the RISC philosophy, and x86, based on the CISC philosophy.
The x86 processors, popularized by Intel, are widely adopted in personal computers, with the exception of the recent MacBooks (M1 and M2 models), which use chips based on the ARM architecture. Historically, the ARM architecture had limited adoption in personal computers but gained prominence and popularity with the advent of smartphones. The situation changed significantly when Apple launched its first M1 chip in 2020, marking a significant return of the ARM architecture to the personal computer market, this time with broader adoption thanks to its performance and energy efficiency.
To understand the performance of a processor, it's crucial to consider not only the operating frequency but also other factors such as the efficiency of instructions, the processor architecture design, including its pipeline system, cache, and the ability to maximize the IPC. Moreover, modern technologies, such as out-of-order execution, branch prediction, and advanced pipeline techniques, play a significant role in optimizing the performance and efficiency of contemporary processors.
Therefore, while the clock frequency and max-IPC are important indicators of a processor's capacity, the reality of performance is multifaceted, involving a balance between various critical components of the processor's architecture.
Before delving further into ARM and x86 models, a basic introduction to the underlying architectural philosophies - The architectural philosophy underlying the ARM and x86 implementations: RISC and CISC.
RISC & CISC
RISC and CISC are two distinct philosophies/architectures, technically called ISA - Instruction Set Architecture, for prototyping processor chips.
In the early days of computing (before 1970), most resources that are abundant today were limited and expensive. Especially memory was an absurdly expensive resource, and because of this, instructions for computers needed to be optimized to use as little storage space as possible. Moreover, there were obviously no programming languages (C had not yet been developed), so programming was performed close to the hardware level - in machine language or Assembly language. Thus, it made total sense to reduce the amount of code necessary to perform tasks (less code == less use of memory and lower likelihood of human errors), and from this emerged the CISC philosophy.
The purpose of CISC - Complex Instruction Set Computer - was to reduce the amount of code necessary to perform complex tasks, as its approach was based on executing several low-level operations in a single call, applying something known as “multi-cycle instructions”. A single instruction can perform various operations, such as loading data into memory, performing an arithmetic operation, and storing the result back in memory - again, all in a single instruction. In addition, CISC also offers various instructions that facilitate access to memory: Direct, indirect, immediate access, and especially the indexed and based modes - This is a bit more complex, but for simplicity, assume that these two are essentially more complex because they involve combinations of addresses with values. The trade-off in this case is that as the instruction is complex, it requires a greater number of cycles to complete that instruction.
Again, all of this made sense for the time, given the resource limitations.
However, as semiconductor technology evolved during the 70s, with the advent of integrated circuits and the reduction in memory costs (Jack Kilby, Robert Noyce, Robert Dennard were some of the important figures making this possible), the limitations justifying the CISC approach no longer made as much sense, and another approach was proposed: RISC - Reduced Instruction Set Computer.
RISC was formalized through researchers like John Cocke and the legendary IBM 801 project, and John Hennessy from the University of Berkeley and his RISC I. The proposal of RISC is that each instruction is designed to minimize the number of instructions required in the processor's instruction set and that each operation can be completed in just one cycle, making use of simpler operations and smaller size. Each instruction has fixed sizes and performs elementary operations such as, for example, loading some data. Fixed sizes generate pipeline predictability or, in other words, we now know exactly how many instructions can be in a cycle and, with this deterministic behavior, it is possible to employ optimization techniques to have as many instructions as possible at that moment and cycle. At this point in history, C had already been invented, and there was no longer a great need to always program in Assembly, and thus, the complex instructions that previously facilitated the task of programming were now the responsibility of the compiler and not the programmer. Another important implication is that, as instructions are now simpler, it is no longer necessary to have numerous transistors to represent the complex operations that existed in CISC, and this means that with fewer transistors, there is more physical space to add more general-purpose registers - the type of memory access that is the fastest within a computer and allows for "temporary and immediate" access to data necessary for processing. For comparison, an SSD operates with responses in the order of 50 to 150ns. A register operates in the range of 0.3 to 0.5 ns.
Practical Example - RISC & CISC
The RISC approach values simple and quick instructions. Suppose we want to perform a multiplication operation between two numbers. For the sake of this example, let's say this RISC implementation does not have a native operation that simply executes the multiplication operation. How do we proceed?
1 - First, it's necessary to load the first value from memory into register A.
2 - Now, we load the second value from memory into register B.
3 - With the values in the registers, it's now possible to execute the PROD instruction, which multiplies the value in register A by the value in register B. The result is stored in register A.
4 - Finally, we store the result from register A into memory address 2:3.
LOAD A, 2:3
LOAD B, 5:2
PROD A, B
STORE 2:3, ABefore entering any discussion, let's see how this is done in the CISC approach.
The purpose of CISC is to reduce the amount of code necessary to execute complex tasks, and the multiplication operation is relatively elementary and has a generic use, making total sense for this operation to be implemented at the hardware level by the CISC philosophy. So here, the code should be extremely simple:
MULT 2:3, 5:2In one line - a single instruction (MULT) - the 04 instructions were simply abstracted into a single function. It's evident the gain if I'm an Assembly programmer - the instruction is simple, and fewer instructions mean fewer bytes of code that need to be stored in memory.
Performance Strategy
Defining performance in general can be a headache. But trying to be straightforward, we could say that in this case, performance can simply be a measure that evaluates how quickly a program takes to execute - ignoring other aspects like generated heat, etc. Thus, the less time it takes, the more "performant" it will be.
Intuitively, one might think that the fewer instructions I need to execute a program, the faster it will likely execute. Alternatively, the more cycles executed in less time, the higher the performance. Or still, I want more instructions within each cycle, to optimize each cycle. All of this is true and mathematically, we have a sort of equation:
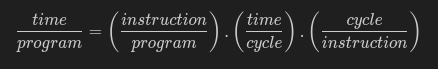
Hence, it becomes evident that higher performance in this case is:
- Less time to execute each cycle;
- Minimize the number of instructions in each program;
- Fewer cycles for each instruction;
Essentially, RISC and CISC work in distinct ways. RISC adopts the strategy of fewer cycles for each instruction at the cost of increasing the number of instructions per program. In turn, the CISC approach is to reduce the number of instructions per program and for this, increases the number of cycles per instruction.
As always, it's a trade-off.
That said, after this long tangent, back to x86 and ARM.
ARM & x86
In very general terms, ARM has simpler instructions and implements a RISC - Reduced Instruction Set Computer type architecture. ARM stands for "Advanced RISC Machine", although its original name was "Acorn RISC Machine".
On the other hand, x86 is a family of CPU architectures that follow the CISC approach. It was originally developed by Intel and has been the standard adopted for personal computers, with the exception of MacBooks M1, M2, or models like Windows Surface.
The CISC architecture was born in a context where memory was extremely expensive. At the time, 1MB of DRAM cost ~$5,000. By 1994, it was about $5, and nowadays, we no longer talk in terms of MB, but rather GB. Windows, since its 3.1 version, was designed to be compatible with CISC architectures, which generated great stability and preference for CISC chips. Despite design challenges, Intel has continued and continues to develop powerful chips today, given the optimization resources the company possesses. RISC was adopted at some points in history, such as was the case with Apple's PowerPCs, but in 2005 it migrated to x86 and in 2020, returned to ARM. The smartphone market, on the other hand, has always been predominantly ARM due to the inherent need for energy savings and performance per Watt spent.
x86, by implementing CISC, has more complex elementary instructions of varied size and complexity. Varied complexity instructions create the problem of making it difficult to predict how many instructions it is possible to run each cycle (clock), in order to optimize and maximize the number of instructions per cycle (clock). And this is exactly what makes the x86 architecture problematic in this sense. x86 instructions have lengths of 1 to 15 bytes, and for this reason, an Intel processor executes on average, 4 to 5 instructions per cycle.
In a scenario of a program that has 10 simple instructions, with 1 to 2 bytes in length and in a sequential manner, the x86 architecture turns out to be quite inefficient, as here a processor could hypothetically run 8 to 10 instructions per clock, but the x86 chip is limited to 4 - 5 instructions per cycle, due to the wide dispersion of sizes of the general instructions on an x86 chip. Therefore, more clocks will be needed to execute these 8 to 10 instructions, which means lower efficiency and higher energy consumption. Chips built based on x86 CISC have shorter instruction pipelines.
On the other hand, ARM chips only have 2 types of instructions: 16-bit or 32-bit instructions (Or 2 bytes and 4 bytes) independently, and to switch between one and the other, there is a specific instruction to change the MODE. Reduced and fixed-size instructions generate predictability. Therefore, knowing what the size of the instructions will be, it is possible to configure the pipeline as long as possible - executing more instructions per clock.
Currently, Apple's M1 chip operating at 2Ghz can execute 8 instructions per clock vs 4-5 instructions for any x86 chip, in the same frequency range. In this sense, an M1 chip has the potential to be 2x faster than an Intel equivalent, at the same clock frequency, or be competitive compared to a 3-4Ghz chip from some x86.
In the field of emulation, an ARM chip can simulate an x86 chip more simply than an x86 can emulate an ARM. This is because ARM has a simpler set of instructions, and therefore, when simulating an x86, it is adapting a complex set of instructions to a simpler one. This is technically facilitated because here it is possible to compensate for the overhead that an x86 instruction generates through aggressive pipelining techniques and optimized use of general-purpose registers (ARM has more general-purpose registers than x86), which decreases the need for access to "slower" memory. In general, ARM processors have TWICE as many general-purpose registers compared to their x86 equivalents. This means there are spare registers, which allows all the arguments needed to form a complex x86 instruction to stay within these registers.
On the other hand, x86 has a more complex set of instructions, and when simulating an ARM, it is necessary for it to replicate the effects of simple instructions, without having those simple instructions. This obviously involves an extra layer of complexity, because this translation is not just about mapping one instruction to another; in general, several x86 instructions (all complex) are needed to replicate the effect of a single ARM instruction. When we talk about emulation, it means translating the instructions in real-time. Here, the number of operations is deliberately increased, creating overhead because each ARM instruction needs to be interpreted, translated, and then executed on x86 hardware - obviously, this increases resource consumption. Additionally, ARM has more general-purpose registers - this means more information is kept close to the processor